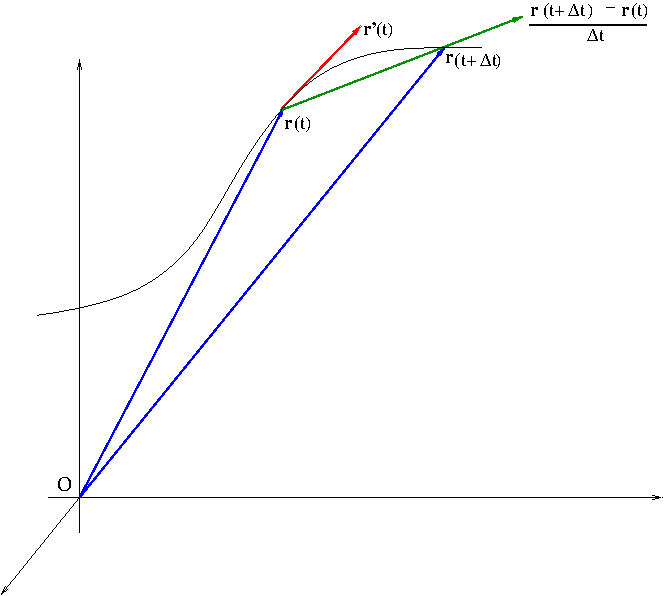
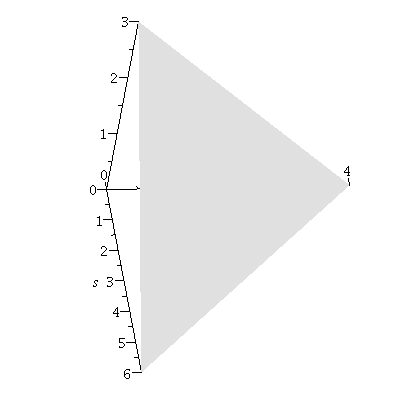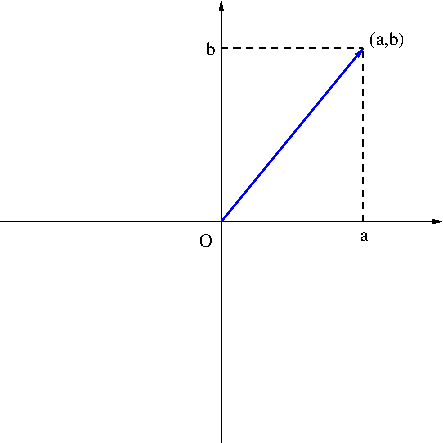The derivative $\frac{d{\bf r}}{dt}={\bf r}'(t)$ of a vector-valued function ${\bf r}(t)=(x(t),y(t),z(t))$ is defined by \begin{equation}\label{eq:vectorderivative}\frac{d{\bf r}}{dt}=\lim_{\Delta t\to 0}\frac{{\bf r}(t+\Delta t)-{\bf r}(t)}{\Delta t}\end{equation} In case of a scalar-valued function or a real-valued function, the geometric meaning of derivative is that it is the slope of tangent line. In case of a vector-valued function, the geometric meaning of derivative is that it is the tangent vector. It can be easily seen from Figure 1. As $\Delta t$ gets smaller and smaller, $\frac{{\bf r}(t+\Delta t)-{\bf r}(t)}{\Delta t}$ gets closer to a line tangent to ${\bf r}(t)$.
Figure 1. The derivative of a vector-valued function
From the definition \eqref{eq:vectorderivative}, it is straightforward to show \begin{equation}\label{eq:vectorderivative2}{\bf r}'(t)=(x'(t),y'(t),z'(t))\end{equation}
If ${\bf r}'(t)\ne 0$, the unit tangent vector ${\bf T}(t)$ of ${\bf r}(t)$ is given by \begin{equation}\label{eq:unittangent}{\bf T}(t)=\frac{{\bf r}'(t)}{|{\bf r}'(t)|}\end{equation}
Example.
Find the derivative of ${\bf r}(t)=(1+t^3){\bf i}+te^{-t}{\bf j}+\sin 2t{\bf k}$.
Find the unit tangent vector when $t=0$.
Solution.
Using \eqref{eq:vectorderivative2}, we have $${\bf r}'(t)=3t^2{\bf i}+(1-t)e^{-t}{\bf j}+2\cos 2t{\bf k}$$
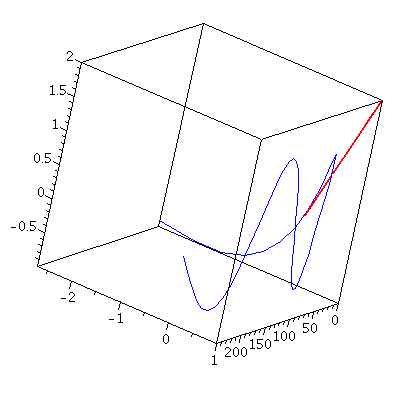
${\bf r}'(0)={\bf j}+2{\bf k}$ and $|{\bf r}'(0)|=\sqrt{5}$. So by \eqref{eq:unittangent}, we have $${\bf T}(0)=\frac{{\bf r}'(0)}{|{\bf r}'(0)|}=\frac{1}{\sqrt{5}}{\bf j}+\frac{2}{\sqrt{5}}{\bf k}$$
Figure 2. The vector-valued function r(t) (in blue) and r'(0) (in red)
The following theorem is a summary of differentiation rules for vector-valued functions. We omit the proofs of these rules. They can be proved straightforwardly from differentiation rules for real-valued functions. Note that there are three different types of the product rule or the Leibniz rule for vector-valued functions (rules 3, 4, and 5).
Theorem. Let ${\bf u}(t)$ and ${\bf v}(t)$ be differentiable vector-valued functions, $f(t)$ a scalar function, and $c$ a scalar. Then
Example. Show that if $|{\bf r}(t)|=c$ (a constant), then ${\bf r}'(t)$ is orthogonal to ${\bf r}(t)$ for all $t$.
Proof. Differentiating ${\bf r}(t)\cdot{\bf r}(t)=|{\bf r}(t)|^2=c^2$ using the Leibniz rule 5, we obtain $$0=\frac{d}{dt}[{\bf r}(t)\cdot{\bf r}(t)]={\bf r}'(t){\bf r}(t)+{\bf r}(t){\bf r}'(t)=2{\bf r}'(t)\cdot{\bf r}(t)$$ This implies that ${\bf r}'(t)$ is orthogonal to ${\bf r}(t)$.
As seen in \eqref{eq:vectorderivative2}, the derivative of a vector-valued functions is obtained by differentiating component-wise. The indefinite and definite integral of a vector-valued function are done similarly by integrating component-wise, namely\begin{equation}\label{eq:vectorintegral}\int{\bf r}(t)dt=\left(\int x(t)dt\right){\bf i}+\left(\int y(t)dt\right){\bf j}+\left(\int z(t)dt\right){\bf k}\end{equation} and \begin{equation}\label{eq:vectorintegral2}\int_a^b{\bf r}(t)dt=\left(\int_a^b x(t)dt\right){\bf i}+\left(\int_a^b y(t)dt\right){\bf j}+\left(\int_a^b z(t)dt\right){\bf k}\end{equation}, respectively. When evaluate the definite integral of a vector-valued function, one can use \eqref{eq:vectorintegral2} but it would be easier to first find the indefinite integral using \eqref{eq:vectorintegral} and then evaluate the definite integral the Fundamental Theorem of Calculus (and yes, the Fundamental Theorem of Calculus still works for vector-valued functions).
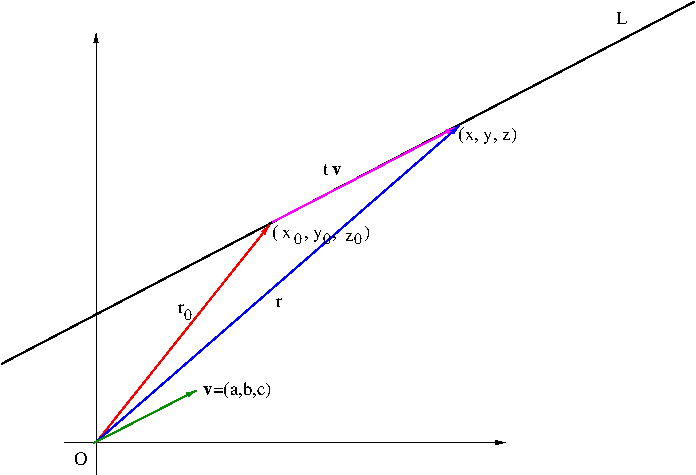
You remember from algebra that a line in the plane can be determined by its slope and a point on the line or two points on the line (in which case those two points determine the slope). For a space line, slope is not a suitable ingredient. It’s alternative ingredient is a vector parallel to the line. As shown in Figure 1, with a point ${\bf r}_0=(x_0,y_0,z_0)$ on the line $L$ and a vector ${\bf v}=(a,b,c)$ parallel to $L$, we can determine any point ${\bf r}=(x,y,z)$ on $L$ by vector addition of ${\bf r}_0$ and $t{\bf v}$, a dilation of ${\bf v}$: \begin{equation}\label{eq:spaceline}{\bf r}={\bf r}_0+t{\bf v}\end{equation} where $-\infty<t<\infty$. The equation \eqref{eq:spaceline} is called a vector equation of $L$.
Figure 1, A space line
In terms of the components, \eqref{eq:spaceline} can be written as \begin{equation}\begin{aligned}x&=x_0+at\\y&=y_0+bt\\z&=z_0+ct\end{aligned}\label{eq:spaceline2}\end{equation} where $-\infty<t<\infty$. The equations in \eqref{eq:spaceline2} are called parametric equations of $L$. Solving the parametric equations in \eqref{eq:spaceline2} for $t$, we also obtain \begin{equation}\label{eq:spaceline3}\frac{x-x_0}{a}=\frac{y-y_0}{b}=\frac{z-z_0}{c}\end{equation} The equations in \eqref{eq:spaceline3} are called symmetric equations of $L$. Often we need to work with a line segment. The vector equation \eqref{eq:spaceline} can be used to figure out an equation of a line segment. Consider the line segment from ${\bf r}_0$ to ${\bf r}_1$. Then the difference ${\bf r}_1-{\bf r}_0$ is a vector parallel to the line segment and by \eqref{eq:spaceline}, we have \begin{align*}{\bf r}(t)&={\bf r}_0+t({\bf r}_1-{\bf r}_0)\\&=(1-t){\bf r}_0+t{\bf r}_1\end{align*} This still represents an infinite line through ${\bf r}_0$ and ${\bf r}_1$. By limiting the range of $t$ to represent only the line segment from ${\bf r}_0$ to ${\bf r}_1$, we obtain an equation of the line segment \begin{equation}\label{eq:linesegment}{\bf r}(t)=(1-t){\bf r}_0+t{\bf r}_1\end{equation} where $0\leq t\leq 1$.
Example.
Find a vector equation and parametric equations for the line that passes through the point $(5,1,3)$ and is parallel to the vector ${\bf i}+4{\bf j}-2{\bf k}$.
Find two other points on the line.
Solution.
${\bf r}_0=(5,1,3)$ and ${\bf v}=(1,4,-2)$. Hence by \eqref{eq:spaceline}, we have $${\bf r}(t)=(5,1,3)+t(1,4,-2)=(5+t,1+4t,3-2t)$$ Parametric equations are $$x(t)=5+t,\ y(t)=1+4t,\ z(t)=3-2t$$
From the parametric equations, for example, $t=1$ gives $(6,5,1)$ and $t=-1$ gives $(4,-3,5)$.
Example.
Find parametric equations and symmetric equations of the line that passes through the points $A(2,4,-3)$ and $B(3,-1,1)$.
At what point does this line intersect the $xy$-plane?
Solution.
Note that the vector ${\bf v}=\overrightarrow{AB}=(1, -5, 4)$ is parallel to the line. So $a=1$, $b=-5$, and $c=4$. By taking ${\bf r}_0=(x_0,y_0,z_0)=(2,4,-3)$, we have the parametric equations $$x=2+t,\ y=4-5t,\ z=-3+4t$$ Symmetric equations are then $$\frac{x-2}{1}=\frac{y-4}{-5}=\frac{z+3}{4}$$
The line intersects the $xy$-plane when $z=0$. By setting $z=0$ in the symmetric equations from part 1, we get $$\frac{x-2}{1}=\frac{y-4}{-5}=\frac{3}{4}$$ Solving these equations for $x$ and $y$ respectively, we find $x=\frac{11}{4}$ and $y=\frac{1}{4}$.
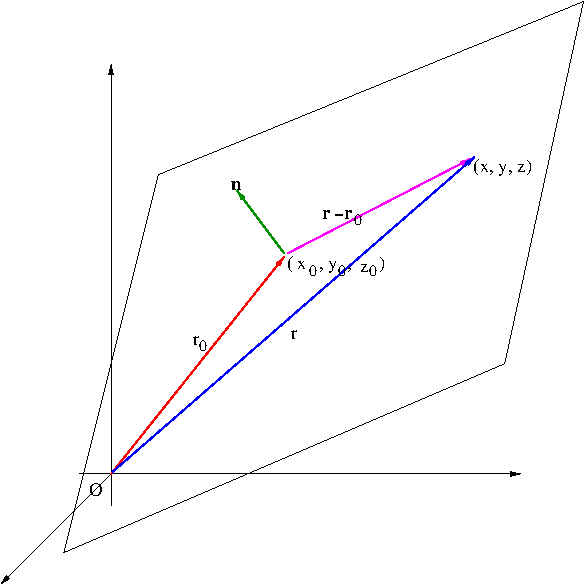
As we have seen, a line is determined by a point on the line and a vector parallel to the line. A plane, on the other hand, can be determined by a point ${\bf r}_0$ on the plane and a vector ${\bf n}$ perpendicular to the plane (such a vector is called a normal vector to the plane). See Figure 2.
Figure 2. A plane
From Figure 2, we see that \begin{equation}\label{eq:plane}{\bf n}\cdot({\bf r}-{\bf r}_0)=0\end{equation} The equation \eqref{eq:plane} is called a vector equation of the plane. If ${\bf n}=(a,b,c)$, ${\bf r}=(x,y,z)$, and ${\bf r}_0=(x_0,y_0,z_0)$, then the equation \eqref{eq:plane} can be written as \begin{equation}\label{eq:plane2}a(x-x_0)+b(y-y_0)+c(z-z_0)=0\end{equation}
Example. Find an equation of the plane through the point $(2,4,-1)$ with normal vector ${\bf n}=(2,3,4)$. Find the intercepts and sketch the plane.
Solution. $a=2$, $b=3$, $c=4$, $x_0=2$, $y_0=4$, and $z_0=-1$. So by the equation \eqref{eq:plane2}, we have $$2(x-2)+3(y-4)+4(z+1)=0$$ or $$2x+3y+4z=12$$ To find the $x$-intercept, set $y=z=0$ in the equation and we get $x=6$. Similarly, we find the $y$- and $z$-intercepts $y=4$ and $z=3$, respectively. Figure 3 shows the plane.
Figure 3. Plane 2x+3y+4z=12
Example. Find an equation of the plane that passes through the points $P(1,3,2)$, $Q(3,-1,6)$, and $R(5,2,0)$.
Solution. The vectors $\overrightarrow{PQ}=(2,-4,4)$ and $\overrightarrow{PR}=(4,-1,-2)$ are on the plane, so the cross product $$\overrightarrow{PQ}\times\overrightarrow{PR}=\begin{vmatrix}{\bf i} & {\bf j} & {\bf k}\\2 & -4 & 4\\4 & -1 & -2\end{vmatrix}=12{\bf i}+20{\bf j}+14{\bf k}$$ is a normal vector to the plane. With $(x_0,y_0,z_0)=(1,3,2)$ and $(a,b,c)=(12,20,14)$, we find an equation of the plane $$12(x-1)+20(y-3)+14(z-2)=0$$ or $$6x+10y+7z=50$$
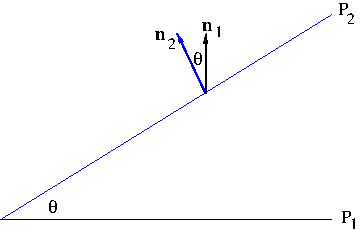
Using basic geometry, we see that the angle between two planes $P_1$ and $P_2$ is the same as the angle between their respective normal vectors ${\bf n}_1$ and ${\bf n}_2$. See Figure 4 where cross sections of two planes $P_1$ and $P_2$ are shown.
Figure 4. The angle between two planes P1 and P2
Example.
Find the angle between the planes $x+y+z=1$ and $x-2y+3z=1$.
Find the symmetric equations for the line of intersection $L$ of these two planes
Solution.
The normal vectors of these planes are ${\bf n}_1=(1,1,1)$ and ${\bf n}_2=(1,-2,3)$. Let $\theta$ be the angle between ${\bf n}_1$ and ${\bf n}_2$ . Then $$\cos\theta=\frac{{\bf n}_1\cdot{\bf n }_2}{|{\bf n}_1||{\bf n}_2|}=\frac{1(1)+1(-2)+1(3)}{\sqrt{1^2+1^2+1^2}\sqrt{1^2+(-2)^2+3^2}}=\frac{2}{\sqrt{42}}$$ Thus, $$\theta=\cos^{-1}\left(\frac{2}{\sqrt{42}}\right)\approx 72^\circ$$
First, let us find a point on $L$. Set $z=0$. Then we have $x+y=1$ and $x-2y=1$. Solving these two equations simultaneously we find $x=1$ and $y=0$. So $(1,1,0)$ is on the line $L$. Now we need a vector parallel to the line $L$. The cross product $${\bf n}_1\times{\bf n}_2=\begin{vmatrix}{\bf i} & {\bf j} & {\bf k}\\1 & 1 & 1\\1 & -2 & 3\end{vmatrix}=5{\bf i}-2{\bf j}-3{\bf k}$$ is perpendicular to both ${\bf n}_1$ and ${\bf n}_2$, hence it is parallel to $L$. Therefore, the symmetric equations of $L$ are $$\frac{x-1}{5}=\frac{y}{-5}=\frac{z}{-3}$$
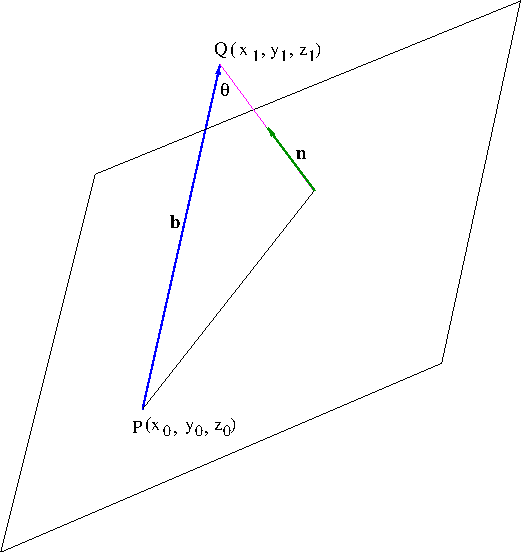
Let us find the distance $D$ from a point $Q(x_1,y_1,z_1)$ to the plane $ax+by+cz+d=0$. See Figure 5.
Figure 5. The distance from a point to a plane
Let $P(x_0,y_0,z_0)$ be a point in the plane and let ${\bf b}=\overrightarrow{PQ}=(x_1-x_0,y_1-y_0,z_1-z_0)$. Then from Figure 5, we see that the distance from $Q$ to the plane is given by the scalar projection of ${\bf b}$ onto the normal vector ${\bf n}$: \begin{align*}D&=|\mathrm{comp}_{\bf n}{\bf b}|=\frac{|{\bf b}\cdot{\bf n}|}{|{\bf n}|}\\&=\frac{|a(x_1-x_0)+b(y_1-y_0)+c(z_1-z_0)|}{\sqrt{a^2+b^2+c^2}}\\&=\frac{|ax_1+by_1+cz_1+d|}{\sqrt{a^2+b^2+c^2}}\end{align*} The last expression is obtained by the fact that $ax_0+by_0+cz_0=-d$. Therefore, the distance $D$ from a point $Q(x_1,y_1,z_1)$ to the plane $ax+by+cz+d=0$ is \begin{equation}\label{eq:distance2plane}D=\frac{|ax_1+by_1+cz_1+d|}{\sqrt{a^2+b^2+c^2}}\end{equation}
Example. Find the distance between the parallel planes $10x+2y-2z=5$ and $5x+y-z=1$.
Solution. One can easily see that the two planes are parallel because their respective normal vectors $(10,2,-2)$ and $(5,1,-1)$ are parallel. To find the distance between the planes, first one will have to find a point in one plane and then use the formula \eqref{eq:distance2plane} to find the distance. Let us find a point in the plane $10x+2y-2z=5$. One can, for instance, use the $x$-intercept, so let $y=z=0$. Then $10x=5$ i.e. $x=\frac{1}{2}$. The distance from $\left(\frac{1}{2},0,0\right)$ to the plane $5x+y-z=1$ is $$D=\frac{\left|5\left(\frac{1}{2}\right)+1(0)-(0)\right|}{\sqrt{5^2+1^2+(-1)^2}}=\frac{\sqrt{3}}{6}$$
Examples in this note have been taken from [1].
References.
[1] Calculus, Early Transcendentals, James Stewart, 6th Edition, Thompson Brooks/Cole
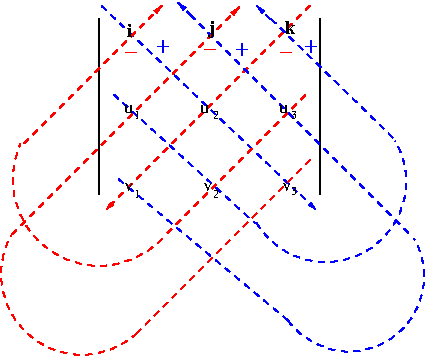
Definition. Let ${\bf u}=(u_1,u_2,u_3)$ and ${\bf v}=(v_1,v_2,v_3)$. Then the cross product ${\bf u}\times {\bf v}$ is defined by \begin{equation}\label{eq:crossprod}{\bf u}\times{\bf v}=(u_2v_3-u_3v_2,u_3v_1-u_1v_3,u_1v_2-u_2v_1)\end{equation} The cross product can be also written as the determinant \begin{equation}\label{eq:crossprod2}{\bf u}\times{\bf v}=\begin{vmatrix}{\bf i} & {\bf j} & {\bf k}\\u_1 & u_2 & u_3\\v_1 & v_2 & v_3\end{vmatrix}\end{equation} One can calculate the determinant as shown in Figure 1. You multiply three entries along each indicated arrow. When you multiply three entries along each red arrow, you also multiply by −1. This is called the Rule of Sarrus named after a French mathematician Pierre Frédéric Sarrus.
Figure 1. The Cross Product
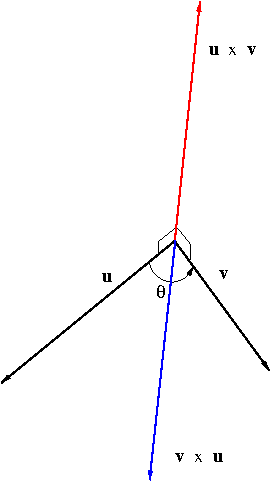
Unlike the dot product, the outcome of the dot product is a vector. Also unlike the dot product, the cross product is anticommutative i.e. $${\bf u}\times{\bf v}=-{\bf v}\times{\bf u}$$ Furthermore, ${\bf u}\times{\bf v}$ is orthogonal to both ${\bf u}$ and ${\bf v}$. This can be seen by showing that $$({\bf u}\times{\bf v})\cdot{\bf u}=({\bf u}\times{\bf v})\cdot{\bf v}=0$$ The cross product tells us about the orientation of the plane containing two vectors ${\bf u}$ and ${\bf v}$ as shown in Figure 2.
Figure 2. The orientations
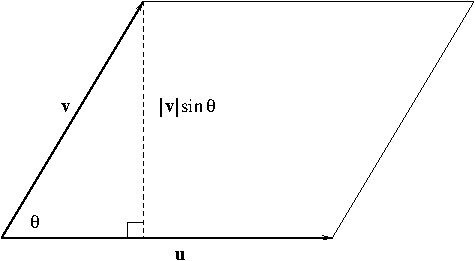
Theorem. If $\theta$ is the angle between ${\bf u}$ and ${\bf v}$ ($0\leq\theta\leq\pi$), then \begin{equation}\label{eq:crossprod3}|{\bf u}\times{\bf v}|=|{\bf u}||{\bf v}|\sin\theta\end{equation}
Proof. It would require some work with algebra but one can show that $$|{\bf u}\times{\bf v}|^2=|{\bf u}|^2|{\bf v}|^2-({\bf u}\cdot{\bf v})^2$$ This, along with ${\bf u}\cdot{\bf v}=|{\bf u}||{\bf v}|\cos\theta$, will lead to \eqref{eq:crossprod3}.
From \eqref{eq:crossprod3}, we can easily see that two nonzero vectors ${\bf u}$ and ${\bf v}$ are parallel if and only if ${\bf u}\times{\bf v}=0$.
The standard basis vectors ${\bf i}$, ${\bf j}$, ${\bf k}$ satisfy the following cross products: $${\bf i}\times{\bf j}={\bf k},\ {\bf j}\times{\bf k}={\bf i},\ {\bf k}\times{\bf i}={\bf j}$$
The following theorem summarizes the properties of the cross product.
Theorem. Let ${\bf u}$, ${\bf v}$, and ${\bf w}$ be vectors and $c$ a scalar. Then
The products in 5 and 6 are called, respectively, a scalar triple product and a vector triple product.
From Figure 3, we see that \begin{equation}\label{eq:areaparallelogram}|{\bf u}\times{\bf v}|\end{equation} is equal to the area of the parallelogram determined by ${\bf u}$ and ${\bf v}$.
Figure 3. The area of a parallelogram
Example. Find a vector perpendicular to the plane that passes through the points $P(1,4,6)$, $Q(-2,5,-1)$, and $R(1,-1,1)$.
Solution. The vectors $\overrightarrow{PQ}=(-3,1,-7)$ and $\overrightarrow{PR}=(0,-5,-5)$ lie in the plane through $P,Q,R$. So the cross product $$\overrightarrow{PQ}\times\overrightarrow{PR}=(-40,-15,15)$$ is perpendicular to the plane.
Example. Find the area of the triangle with vertices $P(1,4,6)$, $Q(-2,5,-1)$, and $R(1,-1,1)$.
Solution. In the previous example, we found $\overrightarrow{PQ}\times\overrightarrow{PR}=(-40,-15,15)$ and by \eqref{eq:areaparallelogram} we know that $|\overrightarrow{PQ}\times\overrightarrow{PR}|=\sqrt{(-40)^2+(-15)^2+{15}^2}=5\sqrt{82}$ is the area of the parallelogram determined by the two vectors $\overrightarrow{PQ}$ and $\overrightarrow{PR}$. The area of the triangle with vertices $P$, $Q$, and $R$ is just the half of the area of the parallelogram i.e. $\frac{5}{2}\sqrt{82}$.
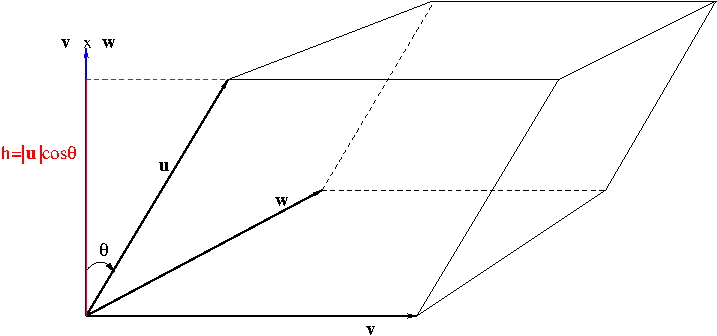
From Figure 4, the volume of the parallelepiped determined by ${\bf u}$, ${\bf v}$, and ${\bf w}$ is $$V=|{\bf v}\times{\bf w}||{\bf u}|\cos\theta={\bf u}\cdot({\bf v}\times{\bf w})$$ In Figure 4, the vectors ${\bf u}$, ${\bf v}$, and ${\bf w}$ are positioned well enough so that the triple scalar product ${\bf u}\cdot({\bf v}\times{\bf w})$ is positive but depending on how they are positioned, it could be negative. Since the volume always has to be positive, it is given by \begin{equation}\label{eq:volumeparallelepiped}V=|{\bf u}\cdot({\bf v}\times{\bf w})|\end{equation}
Figure 4. The volume of a parallelepiped
The scalar triple product ${\bf u}\cdot({\bf v}\times{\bf w})$ can be written nicely by the determinant \begin{equation}\label{eq:scalartripleprod}{\bf u}\cdot({\bf v}\times{\bf w})=\begin{vmatrix}u_1 & u_2 & u_3\\v_1 & v_2 & v_3\\w_1 & w_2 & w_3\end{vmatrix}\end{equation} The calculation of the determinant can be done by the rule of Sarrus shown in Firgure 1.
Example. Determine if ${\bf u}=(1,4,-7)$, ${\bf v}=(2,-1,4)$, and ${\bf w}=(0,-9,18)$ are coplanar.
Solution. From Figure 4 above, one can easily see that the three vectors ${\bf u}$, ${\bf v}$ and ${\bf w}$ are coplanar (i.e. they are in the same plane) if and only if $\theta=\frac{\pi}{2}$ if and only if ${\bf u}\cdot ({\bf v}\times{\bf w})=0$. \begin{align*}{\bf u}\cdot ({\bf v}\times{\bf w})&=\begin{vmatrix}1 & 4 & -7\\2 & -1 & 4\\0 & -9 & 18\end{vmatrix}\\&=0\end{align*} Therefore, ${\bf u}$, ${\bf v}$ and ${\bf w}$ are coplanar.
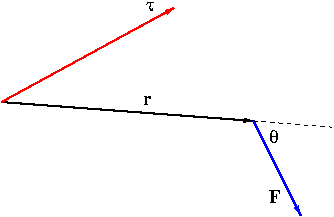
The notion of the cross product can be used to describe physical effects involving rotations such as the circulation of electric/magnetic fields or fluids. Here we discuss the torque as a physical application of the cross product. Look at Figure 5.
Figure 5. Torque
Assume that a force ${\bf F}$ is acting on a rigid body at a point given by a position vector ${\bf r}$. The resulting turning effect ${\bf\tau}$, called the torque, can be measured by \begin{equation}\label{eq:torque}{\bf\tau}={\bf r}\times{\bf F}\end{equation}
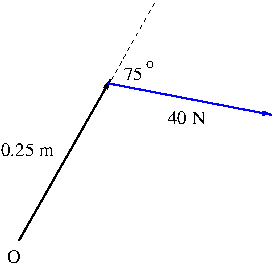
Example. A bolt is tightened by applying a 40 N force to a 0.25 m wrench as shown in Figure 6. Find the magnitude of the torque about the center of the bolt.
Figure 6. Toque
Solution. The magnitude of the torque is \begin{align*}|{\bf\tau}|&=|{\bf r}\times{\bf F}|=|{\bf r}||{\bf F}|\sin 75^\circ=(0.25)(40)\sin 75^\circ\\&=10\sin 75^\circ\approx 9.66\ \mathrm{Nm}\end{align*}
Examples in this note have been taken from [1].
References.
[1] Calculus, Early Transcendentals, James Stewart, 6th Edition, Thompson Brooks/Cole
Definition. Let ${\bf u}=(u_1,u_2,u_3)$ and ${\bf v}=(v_1,v_2,v_3)$. Then the dot product ${\bf u}\cdot{\bf v}$ is defined by $${\bf u}\cdot{\bf v}=u_1v_1+u_2v_2+u_3v_3$$
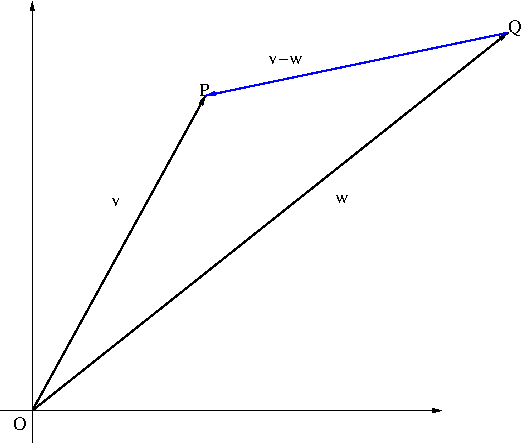
The name “product” is misleading as it is not really an operation. The reason is simple because the outcome of a dot product is a scalar, not a vector. So what is a big deal about this dot product? The dot product defines the length of a vector. Let ${\bf u}=(u_1,u_2,u_3)$. Then $$|{\bf u}|=\sqrt{{\bf u}\cdot {\bf u}}=\sqrt{u_1^2+u_2^2+u_3^3}$$ Furthermore it can also define the distance between two points in space as shown in Figure 1:
Figure 1. Distance between two point P and Q
Let two position vectors ${\bf v}=(v_1,v_2,v_3)$ and ${\bf w}=(w_1,w_2.w_3)$ respectively represent points $P$ and $Q$ in space. The the distance $\overline{PQ}$ between the two points $P$ and $Q$ is the length of the vector ${\bf v}-{\bf w}$ $$\overline{PQ}=|{\bf v}-{\bf w}|=\sqrt{({\bf v}-{\bf w})\cdot({\bf v}-{\bf w})}=\sqrt{(v_1-w_1)^2+(v_2-w_2)^2+(v_3-w_3)^2}$$
Although this is beyond the scope of our discussion here, I would like to mention that the notion of the dot product can be generalized so that it can give rise to a different kind of length. Such generalization is called a scalar product or an inner product. You can read more about it here in case you are interested. A scalar product would satisfy the properties 1-4 in the above theorem. The dot product is associated with the length we are most familiar with, called the Euclidean length but that is not the only kind of length out there. For example, in the vector space of continuous functions on the closed interval $[0,1]$ (which was mentioned here), the scalar product of two functions $f$ and $g$, denoted by $\langle f,g\rangle$ is defined by $$\langle f,g\rangle=\int_0^1 f(x)g(x)dx$$ and the length of $f$ is defined by $$|f|=\sqrt{\langle f,f\rangle}=\sqrt{\int_0^1|f(x)|^2dx}$$ This type of a scalar product plays a very important role in quantum mechanics. It is used to measure the probability of a particle (such as an electron) to be in a particular quantum mechanical state.
There is an alternative description of the dot product.
Theorem. If $\theta$ is the angle between the vectors ${\bf u}$ and ${\bf v}$, where $0\leq\theta\leq\pi$, then \begin{equation}\label{eq:dotproduct}{\bf u}\cdot{\bf v}=|{\bf u}||{\bf v}|\cos\theta\end{equation}
Proof. By applying the Law of Cosines to triangle $\triangle OPQ$ in Figure 1, we obtain \begin{equation}\label{eq:lawcosine}|{\bf u}-{\bf v}|^2=|{\bf u}|^2+|{\bf v}|^2-2|{\bf u}||{\bf v}|\cos\theta\end{equation} \begin{align*}|{\bf u}-{\bf v}|^2&=({\bf u}-{\bf v})\cdot({\bf u}-{\bf v})\\&={\bf u}\cdot{\bf u}-{\bf u}\cdot{\bf v}-{\bf v}\cdot{\bf u}+{\bf v}\cdot{\bf v}\\&=|{\bf u}|^2-2{\bf u}\cdot{\bf v}+|{\bf v}|^2\end{align*}Replacing $|{\bf u}-{\bf v}|^2$ in \eqref{eq:lawcosine} by this last expression results in $$|{\bf u}|^2-2{\bf u}\cdot{\bf v}+|{\bf v}|^2=|{\bf u}|^2+|{\bf v}|^2-2|{\bf u}||{\bf v}|\cos\theta$$ and this simplifies to $${\bf u}\cdot{\bf v}=|{\bf u}||{\bf v}|\cos\theta$$
Example. Find the angle between the vector ${\bf u}=(2,2,-1)$ and ${\bf v}=(5,-3,2)$.
The alternative description of the dot product in \eqref{eq:dotproduct} is usually introduced as the definition of the dot product in high school/freshmen physics course.
From \eqref{eq:dotproduct}, we see that two vectors ${\bf u}$ and ${\bf v}$ are perpendicular or orthogonal (i.e. the angle $\theta$ between ${\bf u}$ and ${\bf v}$ is $\frac{\pi}{2}$) if and only if ${\bf u}\cdot{\bf v}=0$.
Example. $2{\bf i}+2{\bf j}-{\bf k}$ is perpendicular to $5{\bf i}-4{\bf j}+2{\bf k}$ because $$(2{\bf i}+2{\bf j}-{\bf k})\cdot(5{\bf i}-4{\bf j}+2{\bf k})=2(5)+2(-4)+(-1)(2)=0$$
This is beyond the scope of our discussion here but the notion of orthogonality of two vectors can be extended to higher dimensional spaces or more abstract vector spaces by defining that: two vectors ${\bf u}$ and ${\bf v}$ are said to be orthogonal if $\langle{\bf u},{\bf v}\rangle=0$, where $\langle\ ,\ \rangle$ denotes a scalar product. In our case, $\langle{\bf u},{\bf v}\rangle={\bf u}\cdot{\bf v}$. For example, Let $V$ be the set of all continuous functions on the closed interval $[-1,1]$. Then $V$ is a vector space with addition and scalar multiplication defined in the usual way that I discussed here. Also $\langle\ ,\ \rangle$ defined by $$\langle f,g\rangle=\int_{-1}^1f(x)g(x)dx$$ for $f,g\in V$ is a scalar product. The two functions $\sin(2n\pi x)$ and $\cos(2n\pi x)$ are continuous on $[-1,1]$ so they belong to $V$ i.e. they are vectors. They are also orthogonal because $$\langle\sin(2n\pi x),\cos(2n\pi x)\rangle=\int_{-1}^1\sin(2n\pi x)\cos(2n\pi x)dx=0$$
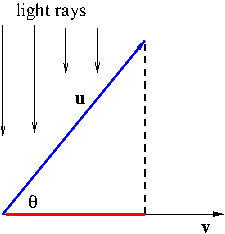
Let us take a look at Figure 2.
Figure 2. Scalar projection
Imagine that light rays coming down on the vector ${\bf u}$ at the direction perpendicular to the vector ${\bf v}$. The the shadow of ${\bf u}$ will be cast on ${\bf v}$ (the red line segment in Figure 2). Mathematically, this shadow is called the orthographic projection of ${\bf u}$ onto ${\bf v}$. In fact, the red line segment is the orthographic projection of the length of the vector ${\bf u}$ onto ${\bf v}$. We denote it by $\mathrm{comp}_{\bf v}{\bf u}$ and call it the scalar projection of ${\bf u}$ onto ${\bf v}$. Using basic trigonometry, we can easily find that $$\mathrm{comp}_{\bf v}{\bf u}=|{\bf u}|\cos\theta$$ However, we prefer to express the scalar projection free of the angle $\theta$ i.e. in terms of only ${\bf u}$ and ${\bf v}$. This can be done using \eqref{eq:dotproduct}: \begin{align*}\mathrm{comp}_{\bf v}{\bf u}&=|{\bf u}|\cos\theta\\&=|{\bf u}|\frac{{\bf u}\cdot{\bf v}}{|{\bf u}||{\bf v}|}\\&=\frac{{\bf u}\cdot{\bf v}}{|{\bf v}|}\end{align*} Hence we obtained our preferred form of the scalar projection \begin{equation}\label{eq:scalarprojection}\mathrm{comp}_{\bf v}{\bf u}=\frac{{\bf u}\cdot{\bf v}}{|{\bf v}|}\end{equation} One can also consider the vector projection of ${\bf u}$ onto ${\bf v}$. All you have to do is to multiplying the scalar projection \eqref{eq:scalarprojection} by the direction of ${\bf v}$: \begin{equation}\label{eq:vectorprojection}\mathrm{proj}_{\bf v}{\bf u}=\mathrm{comp}_{\bf v}{\bf u}\frac{{\bf v}}{|{\bf v}|}=\frac{{\bf u}\cdot{\bf v}}{|{\bf v}|^2}{\bf v}\end{equation}
Example. Find the scalar projection and the vector projection of ${\bf u}=(1,1,2)$ onto ${\bf v}=(-2,3,1)$.
Solution. The scalar projection is $$\mathrm{comp}_{\bf v}{\bf u}=\frac{{\bf u}\cdot{\bf v}}{|{\bf v}|}=\frac{1(-2)+1(3)+2(1)}{\sqrt{(-2)^2+3^2+1^2}}=\frac{3}{\sqrt{14}}$$ The direction of ${\bf v}$ is $\frac{1}{\sqrt{14}}(-2,3,1)$. Hence, the vector projection is $$\mathrm{proj}_{\bf v}{\bf u}=\mathrm{comp}_{\bf v}{\bf u}\frac{1}{\sqrt{14}}(-2,3,1)=\frac{3}{14}(-2,3,1)=\left(-\frac{3}{7},\frac{9}{14},\frac{3}{14}\right)$$
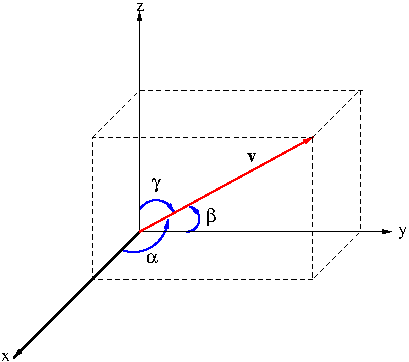
Consider a vector ${\bf v}=(v_1,v_2,v_3)$ in space. The angle $\alpha$ between ${\bf v}$ and ${\bf i}$, the angle $\beta$ between ${\bf v}$ and ${\bf j}$, and the angle $\gamma$ between ${\bf v}$ and ${\bf k}$ are called the direction angles of ${\bf v}$. (See Figure 3.)
Figure 3. Direction angles
Now, \begin{equation}\begin{aligned}\cos\alpha&=\frac{{\bf v}\cdot{\bf i}}{|{\bf v}||{\bf i}|}=\frac{v_1}{|{\bf v}|}\\\cos\beta&=\frac{{\bf v}\cdot{\bf j}}{|{\bf v}||{\bf j}|}=\frac{v_2}{|{\bf v}|}\\\cos\gamma&=\frac{{\bf v}\cdot{\bf k}}{|{\bf v}||{\bf k}|}=\frac{v_3}{|{\bf v}|}\end{aligned}\label{eq:directioncosine}\end{equation} $\cos\alpha$, $\cos\beta$ and $\cos\gamma$ are called the direction cosines of vector ${\bf v}$. It follows from \eqref{eq:directioncosine} that $(\cos\alpha,\cos\beta,\cos\gamma)$ is the direction of ${\bf v}$, hence the name directions cosines.
Example. Find the direction angles of the vector ${\bf v}=(1,2,3)$.
Solution. $|{\bf v}|=\sqrt{1^2+2^2+3^2}=\sqrt{14}$. Using \eqref{eq:directioncosine}, we have \begin{align*}\alpha&=\cos^{-1}\left(\frac{1}{\sqrt{14}}\right)\approx 74^\circ\\\beta&=\cos^{-1}\left(\frac{2}{\sqrt{14}}\right)\approx 58^\circ\\\gamma&=\cos^{-1}\left(\frac{3}{\sqrt{14}}\right)\approx 37^\circ\end{align*}
Work
Consider a linear motion i.e. a motion of an object along a straight line. See Figure 4.
Figure 4. Work
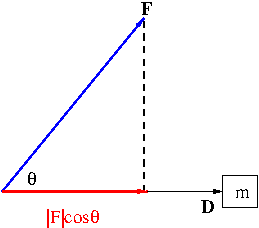
Suppose that an object is moved by a force ${\bf F}$. If the displacement is ${\bf D}$, then the work $W$ done by this force ${\bf F}$ is defined by the scalar projection of ${\bf F}$ onto ${\bf D}$, $|{\bf F}|\cos\theta$ (this is the component of ${\bf F}$ that actually moved the object) times the distance moved $|{\bf D}|$: \begin{equation}\label{eq:work}W={\bf F}\cdot{\bf D}\end{equation}
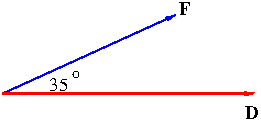
Example. A wagon is pulled a distance of 100 m along a horizontal path by a constant force of 70 N. The handle of the wagon is held at an angle of $35^\circ$ above the horizontal. Find the work done by the force.
Solution. The force ${\bf F}$ and the displacement ${\bf D}$ are as depicted in Figure 5.
Figure 5. Work
Thus the work $W$ is \begin{align*}W&={\bf F}\cdot{\bf D}=|{\bf F}||{\bf D}|\cos 35^\circ\\&=70(100)\cos 35^\circ=5734\ \mathrm{J}\end{align*} where J, called Joule, is a unit for work which stands for Newton times meter.
Example. A force given by the vector ${\bf F}=3{\bf i}+4{\bf j}+5{\bf k}$ moves a particle from the point $P(2,1,0)$ to the point $Q(4,6,2)$. Find the work done by the force.
Solution. Here, there is no mention of a particular path the particle is taking. We assume that the motion is again linear. The displacement is ${\bf D}=\overrightarrow{PQ}=(4-2,6-1,2-0)=(2,5,2)$. Hence the work is \begin{align*}W&={\bf F}\cdot{\bf D}=(3,4,5)\cdot(2,5,2)\\&=6+20+10=36\end{align*}
Examples in this note have been taken from [1].
References.
[1] Calculus, Early Transcendentals, James Stewart, 6th Edition, Thompson Brooks/Cole
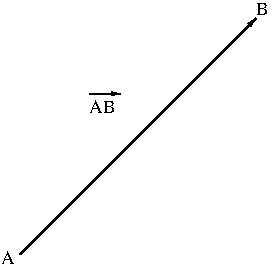
A vector is a quantity that has both direction and magnitude. Examples of vectors include displacement, velocity, force, weight, momentum, etc. A quantity that has only magnitude is called a scalar. Scalars are really just numbers. Examples of scalars include distance, speed, mass, temperature, etc. Since a vector has both direction and magnitude, it can be visually represented by a directed arrow. For instance, if a particle moves from a point $A$ to another point $B$, its displacement (i.e. the shortest distance from $A$ to $B$) is denoted by $\overrightarrow{AB}$ and it is visually represented by a directed arrow as in Figure 1.
Figure 1. A vector
The direction at which the arrow is pointing is the direction of the vector $\overrightarrow{AB}$ and the length of the arrow is the magnitude of the vector $\overrightarrow{AB}$. When it is not necessary to specify the initial point and the terminal point, a vector is denoted by a lower case alphabet letter with arrow on top like $\vec v$ or in boldface like ${\bf v}$.
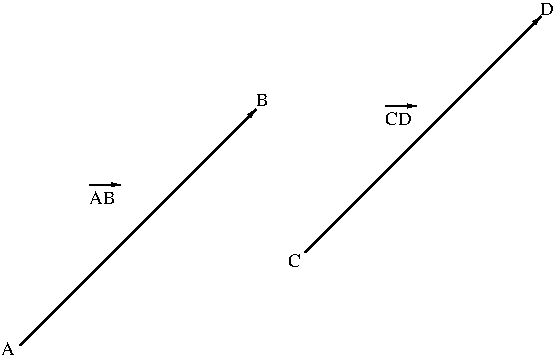
Two vectors are said to be the same or equivalent if they have the same direction and the magnitude regardless of where they are located. If vectors $\overrightarrow{AB}$ and $\overrightarrow{CD}$ are the same, we write $\overrightarrow{AB}=\overrightarrow{CD}$. Figure 2 shows two equivalent vectors $\overrightarrow{AB}$ and $\overrightarrow{CD}$.
Figure 2. Equivalent vectors
The equivalence of two vectors implies that a vector can be moved around maintaining its characters (direction and magnitude) so it stays as the same vector although its location has changed (meaning its initial and terminal points have changed). Moving a vector without changing direction and magnitude is called a parallel translation.
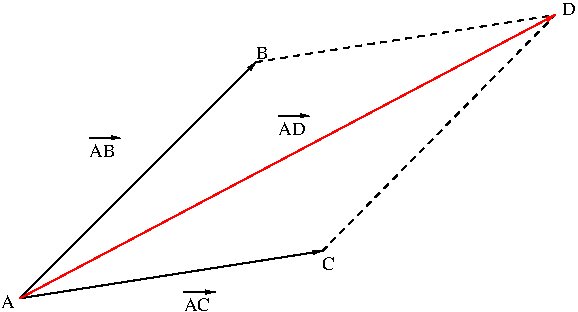
There are two types of operations on vectors. One is vector addition and the other is scalar multiplication. Vector addition is defined pictorially by using a parallelogram or a triangle. Figure 3 shows vector addition $$\overrightarrow{AB}+\overrightarrow{AC}=\overrightarrow{AD}$$ by using a parallelogram.
Figure 3. Vector addition by a parallelogram
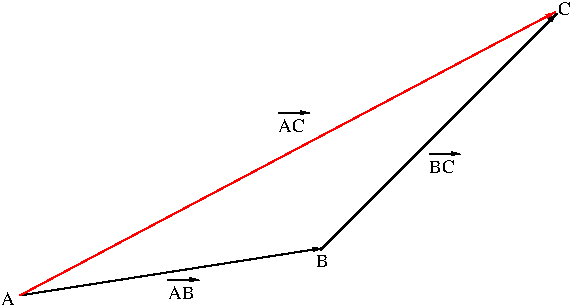
Figure 4 shows vector addition $$\overrightarrow{AB}+\overrightarrow{BC}=\overrightarrow{AC}$$ by using a triangle. The two ways of adding two vectors are indeed equivalent. The only difference is how you locate two vectors to add them together.
Figure 4. Vector addition by a triangle
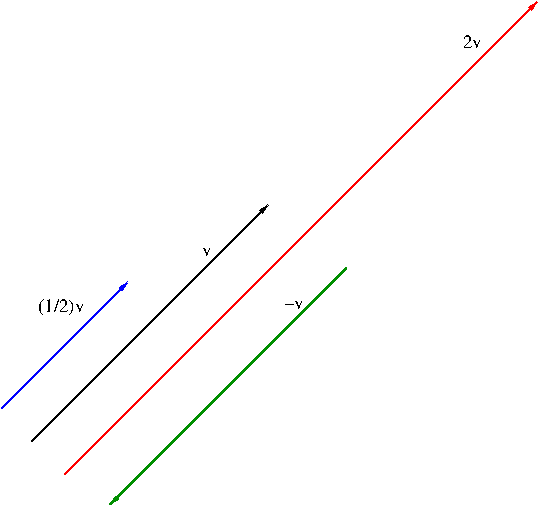
Scalar multiplication is a product between a scalar and a vector. While many people, even some (less careful) mathematicians, consider it as an operation, it is not an operation but an action. I am not going to talk about what an action is here. In case someone is curious, you can visit the Wikipedia page on Group Actionhere. In calculus level, distinction between an operation and an action is not really important at all. Let $c$ be a scalar and $v$ a vector. What the scalar multiplication $c{\bf v}$ does is, depends on the value of $c$, it can stretch (when $c>1$), shrink (when $0<c<1$), or reverse the direction (when $c=-1$) of vector ${\bf v}$ as illustrated in Figure 5.
Figure 5. Scalar multiplication
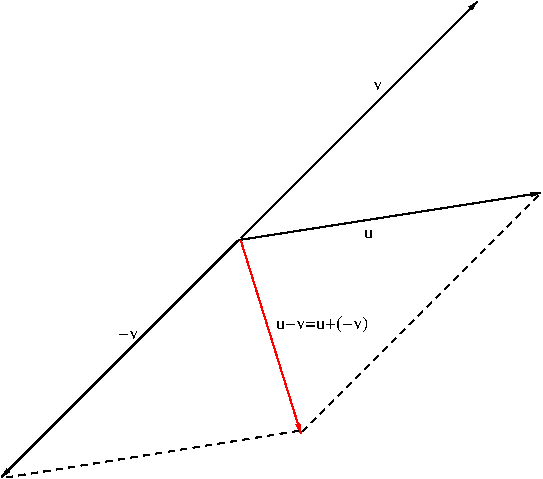
Using vector addition and scalar multiplication, one can define subtraction of a vector ${\bf v}$ from another vector ${\bf u}$: $${\bf u}-{\bf v}:={\bf u}+(-{\bf v})$$ See Figure 6.
Figure 6. Vector substraction
Earlier I mentioned that a vector can be moved around while preserving its direction and magnitude, and a parallel translation of a vector is still considered to be the same as the previous vector, although it is now at a different location. Among all those same vectors, we are particularly interested in vectors that are starting the origin $O$. Figure 7 shows an example of such a vector.
Figure 7. A position vector
A vectors whose initial point is the origin $O$ is called a position vector or a located vector. A position vector is determined only by its terminal point, thereby it can be identified with a point in space and conversely a point in space can be identified with a position vector. For example, if the terminal point of a position vector ${\bf v}$ is $(a_1,a_2,a_3)$, then we regard them the same i.e. ${\bf v}=(a_1,a_2,a_3)$. Why this is such a big deal? The directed arrow representation of a vector has a lot of limitations. The most severe limitation is that it can only be useful when we can see them, i.e. their usage is limited within 3-dimensions as our perception does not allow us to go beyond 3-dimensions. However, Einstein’s theory of relativity (which has also been confirmed by numerous experiments and observations) that our universe is actually 4-dimensional. But that’s the universe we observe right now. String theory tells us that the universe can have up to 26-dimensions. It does not have to go that far beyond though. There are many other places here down on earth including computer science, economics, etc. where the notions of vectors in higher dimensions are being used. Considering position vectors resolve the limitation. Furthermore, now that we identify vectors with points in space and points are represented by ordered $n$-tuples (ordered pairs, triples, quadruples, depending on the dimension of the space) which are algebraic objects, we can use the power of algebra to describe the properties of vectors.
Given the points $A(a_1,a_2,a_3)$ and $B(b_1,b_2,b_3)$, the vector ${\bf v}$ which is represented by the directed arrow $\overrightarrow{AB}$ is $${\bf v}=(b_1-a_1,b_2-a_2,b_3-a_3)$$
Example. Find the vector represented by the directed arrow with initial point $A(2,-3,4)$ and $B(-2,1,1)$.
Solution. ${\bf v}=(-2-2,1-(-3),1-4)=(-4,4,-3)$.
The length or magnitude of a vector ${\bf v}$ is denoted by $|{\bf v}|$. For a vector ${\bf v}=(v_1,v_2)$ in the plane, $|{\bf v}|$ is given by $$|{\bf v}|=\sqrt{v_1^2+v_2^2}$$ (It’s easy to see this from Figure 7 using the Pythagorean law.) Similarly, for a vector ${\bf v}=(v_1,v_2,v_3)$ in space, $$|{\bf v}|=\sqrt{v_1^2+v_2^2+v_3^3}$$ It follows from the definition that \begin{equation}\label{eq:length}|c{\bf v}|=|c||{\bf v}|\end{equation} where $c$ is a scalar.
Vector addition and scalar multiplication can be nicely defined algebraically without using parallelograms or triangles. Furthermore, these algebraic definitions apply to vectors in arbitrary $n$-dimensional space. For vectors ${\bf u}=(u_1,u_2,u_3)$, ${\bf v}=(v_1,v_2,v_3)$ and a scalar $c$, \begin{align*}{\bf u}+{\bf v}&:=(u_1+v_1,u_2+v_2,u_3+v+3)\\c{\bf u}&:=(cu_1,cu_2,cu_3)\end{align*}
${\bf u}+{\bf 0}={\bf u}$, where ${\bf 0}=(0,0,\cdots,0)$
${\bf u}+(-{\bf u})={\bf 0}$
$c({\bf u}+{\bf v})=c{\bf u}+c{\bf v}$
$(c+d){\bf u}=c{\bf u}+d{\bf u}$
$(cd){\bf u}=c(d{\bf u})$
$1{\bf u}={\bf u}$
It turns out the the original definition of vectors as quantities that have both direction and magnitude is quite obsolete and that even the definition of vectors by ordered $n$-tuples is not adequate enough to address much needed a broader notion of vectors arising in modern physics and engineering. For this reason, in modern treatment of vectors we no longer define what an individual vector is but instead we define a vector space. Simply speaking, a set $V$ with addition $+$ and scalar multiplication $\cdot$ satisfying the properties 1-8 is called a vector space, and the elements of $V$ are called vectors. Under this broader notion of vectors, things that were previously inconceivable to become vectors are now considered vectors. For example, $V$ the set of all continuous real-valued functions on the closed interval $[0,1]$ with addition $+$ and scalar multiplication $\cdot$ are defined by: \begin{align*}(f+g)(x)&:=f(x)+g(x)\\(cf)(x)&:=cf(x)\end{align*} for $f,g\in V$ and a scalar $c$. Then it is straightforward to show that the properties 1-8 are satisfied and therefore, $(V,+,\cdot)$ is a vector space and we regard continuous real-valued functions on $[0,1]$ as vectors. In fact, in quantum mechanics wave functions are state vectors. Another example is signal processing where functions are regarded as vectors. We are not going to delve into vector spaces further here. It is a main topic of linear algebra. For those who are curious, more examples of vector spaces can be found here.
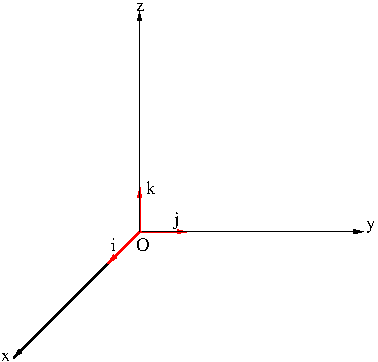
There are infinitely many vectors. So it is humanly impossible to check if a certain property regarding vectors holds for all vectors. However there a particular finite set of vectors, called a basis, that constitute the entire vectors. A vector ${\bf u}=(u_1,u_2,u_3)$ can be written as \begin{equation}\label{eq:lincomb}{\bf u}=u_1(1,0,0)+u_2(0,1,0)+u_3(0,0,1)\end{equation} So we see that any vector can be represented by the three vectors $${\bf i}=(1,0,0),\ {\bf j}=(0,1,0),\ {\bf k}=(0,0,1)$$ by applying vector addition and scalar multiplication finitely many times as in \eqref{eq:lincomb}. The expression on the right hand side of the identity in \eqref{eq:lincomb} is called a linear combination or a superposition of ${\bf i}$, ${\bf j}$, ${\bf k}$. The three vectors ${\bf i}$, ${\bf j}$, ${\bf k}$ are called the canonical or standard basis vectors.
Figure 8. The standard basis
The number of standard basis vectors determines the dimension of the space. The dimension of a space is not necessarily finite though we are considering only finite dimensional spaces here (actually only 2- or 3-dimensional spaces). The set $V$ of all continuous functions on $[0,1]$ is infinite dimensional. The set of all state vectors in a quantum mechanics system is, in general, an infinite dimensional space called a Hilbert space.
Example. If ${\bf u}={\bf i}+2{\bf j}-3{\bf k}$ and ${\bf v}=4{\bf i}+7{\bf k}$, express $2{\bf u}+3{\bf v}$ in terms of ${\bf i}$, ${\bf j}$, ${\bf k}$.
Often in geometry and physics, we are only interested in the direction of a vector. A unit vector is a vector with length 1. Any non-zero vector can be re-scaled to a unit vector with the same direction. All that’s required is dividing the given vector by its magnitude. If ${\bf u}\ne {\bf 0}$, then $$\hat{\bf u}:=\frac{{\bf u}}{|{\bf u}|}$$ is a unit vector which has the same direction as ${\bf u}$: Using \eqref{eq:length}, $$|\hat{\bf u}|=\left|\frac{{\bf u}}{|{\bf u}|}\right|=\frac{1}{|{\bf u}|}|{\bf u}|=1$$
Example. Find the unit vector in the direction of the vector $2{\bf i}-{\bf j}-2{\bf k}$.
Solution. The length of the vector is $\sqrt{2^2+(-1)^2+(-2)^2}=\sqrt{9}=3$. Hence the unit vector with the same direction is $$\frac{2}{3}{\bf i}-\frac{1}{3}{\bf j}-\frac{2}{3}{\bf k}$$
In physics, when several forces are acting on an object, the resultant force or the net force experienced by the object is the vector sum of these forces.
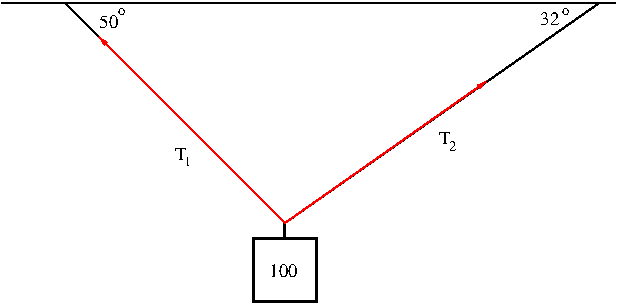
Example. A 100-lb weight hangs from two wires as shown in Figure 9. Find the tension forces ${\bf T}_1$ and ${\bf T}_2$ in both wires and their magnitudes.
Figure 9. The resultant force
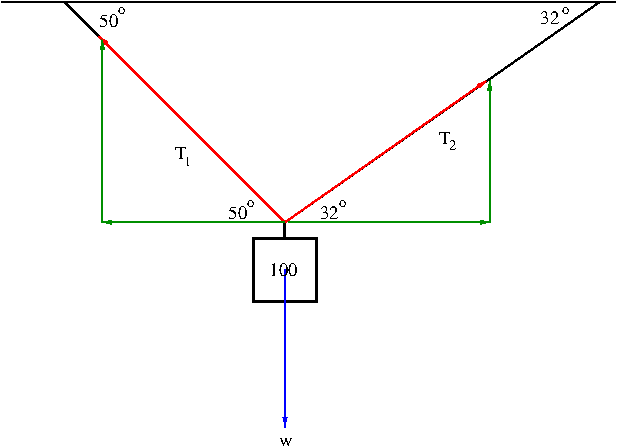
Solution. We first express the tensions ${\bf T}_1$ and ${\bf T}_2$ in terms of their horizontal and vertical components (the vectors in green in Figure 10).
Figure 10. The resultant force
\begin{align}\label{eq:tension1}{\bf T}_1&=-|{\bf T}_1|\cos 50^\circ{\bf i}+|{\bf T}_1|\sin 50^\circ{\bf j}\\\label{eq:tension2}{\bf T}_2&=|{\bf T}_2|\cos 32^\circ{\bf i}+|{\bf T}_2|\sin 32^\circ{\bf j}\end{align} The net force ${\bf T}_1+{\bf T}_2$ of the tensions must counterbalance the weight ${\bf w}$ so that the mass stays hung as in the figure, i.e. $${\bf T}_1+{\bf T}_2=-{\bf w}=100{\bf j}$$ From equations \eqref{eq:tension1} and \eqref{eq:tension2}, we have $$(-|{\bf T}_1|\cos 50^\circ+|{\bf T}_2|\cos 32^\circ){\bf i}+(|{\bf T}_1|\sin 50^\circ+|{\bf T}_2|\sin 32^\circ){\bf j}=100{\bf j}$$ By comparing the components, we obtain the following equations: \begin{align*}-|{\bf T}_1|\cos 50^\circ+|{\bf T}_2|\cos 32^\circ&=0\\|{\bf T}_1|\sin 50^\circ+|{\bf T}_2|\sin 32^\circ&=100\end{align*} Solving these equations simultaneously we find \begin{align*}|{\bf T}_1|&=\frac{100}{\sin 50^\circ+\tan 32^\circ\cos 50^\circ}\approx 85.64\mathrm{lb}\\|{\bf T}_2|&=\frac{|{\bf T}_1|\cos 50^\circ}{\cos 32^\circ}\approx 64.91\mathrm{lb}\end{align*} Therefore, $${\bf T}_1\approx -55.05{\bf i}+65.60{\bf j},\ {\bf T}_2\approx 55.05{\bf i}+34.40{\bf j}$$
Examples in this note have been taken from [1].
References.
[1] Calculus, Early Transcendentals, James Stewart, 6th Edition, Thompson Brooks/Cole