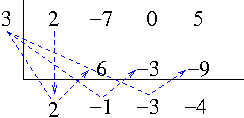As we studied here, once you know how to find at least one rational zero of a polynomial using long division or synthetic division you can find the rest of the zeros of the polynomial. In this note, we study how to find a rational zero of a polynomial if there is one. Let $P(x)=a_nx^n+\cdots +a_1x+a_0$ and suppose that $P(x)$ has a rational zero $\frac{p}{q}$. This means that by factor theorem $P(x)$ has a factor $x-\frac{p}{q}$ or equivalently a factor $qx-p$. That is, $P(x)=(qx-p)Q(x)$ where $Q(x)$ is a polynomial of degree $n-1$. Let us write $Q(x)=b_{n-1}x^{n-1}+\cdots+b_1x+b_0$. Then we see that $a_n=qb_{n-1}$ and $a_0=-pb_0$. This means that $q$ is a factor of the leading coefficient $a_n$ of $P(x)$ and $p$ is a factor of the constant term $a_0$ of $P(x)$. Hence we have the Rational Zero Theorem.
Rational Zero Theorem. Let $P(x)=a_nx^n+\cdots +a_1x+a_0$ be a polynomial with integer coefficients where $a_n\ne 0$ and $a_0\ne 0$. If $P(x)$ has a rationa zero $\frac{p}{q}$ then $q$ is a factor of $a_n$ and $p$ is a factor of $a_0$.
Here is the strategy to find a rational zero of a polynomial $P(x)$.
STEP 1. Use the rational zero theorem to find the all candidates for a rational zero of $P(x)$.
STEP 2. Test each candidate from STEP 1 to see if it is a rational zero using the factor theorem. Once you find one say $\frac{p}{q}$, stop and move to STEP 3
STEP 3. Use long division or synthetic division (easier) to divide $P(x)$ by $x-\frac{p}{q}$ to find the rest of the zeros.
STEP 4. If necessary (in the event $Q(x)$ from STEP 3 has a higher degree), repeat the process $Q(x)$ from STEP 1.
Example. Find all zeros of $P(x)=2x^3+x^2-13x+6$.
Solution. $a_0=2$ has factors $\pm 1$ and $\pm 2$. $a_0=6$ has factors $\pm 1,\pm 2,\pm3\pm 6$. Thus all the candidates for a rational zero are
$$\pm 1,\pm 2,\pm 3,\pm 6,\pm\frac{1}{2},\pm\frac{2}{2}=\pm 1,\pm\frac{3}{2},\pm\frac{6}{2}=\pm 3$$
Since $P(2)=0$, 2 is a rational zero. Using long division or synthetic division we find $Q(x)=2x^2+5x-3=(2x-1)(x+3)$. Therefore, all zeros of $P(x)$ are $-3,\frac{1}{2},2$.
Example. Find all zeros of $P(x)=x^4-5x^3+23x+10$.
Solution. $a_n=1$ has factors $\pm 1$ and $a_0=10$ has factors $\pm 1, \pm 2, \pm 5, \pm10$. So all the candidates for a rational zero are
$$\pm 1, \pm 2, \pm 5, \pm10$$
Since $P(5)=0$, 5 is a rational zero. Using long division or synthetic division we find $Q(x)=x^3-5x-2$. We cannot factor this cubic polynomial readily so we repeat the process. The leading coeffient 1 has factors $\pm 1$ and the constant term $-2$ has factors $\pm 1,\pm 2$ so all the candidates for a rational zero of $Q(x)$ are $\pm 1,\pm 2$. $Q(-2)=0$ so $-2$ is a rational zero of $Q(x)$ (and hence of $P(x)$ as well). Using one’s favorite division we find the quotient $x^2-2x-1$ which has two real zeros $1\pm\sqrt{2}$. Therefore, all zeros of $P(x)$ are
$5, -2, 1\pm\sqrt{2}$.
It would be convenient if we can estimate how many positive real zeros and how many negative zeros without actually factoring the polynomial. Here is a machinary just for that.
Descartes’ Rule of Signs
Let $P(x)$ be a polynomial with real coefficients.
- The number of positive real zeros of $P(x)$ is either equal to the number of variations in sign in $P(x)$ or is less than that by an even number.
- The number of negative real zeros of $P(x)$ is either equal to the number of variations in sign in $P(-x)$ or is less than that by an even number.
Example. $P(x)=3x^6+4x^5+3x^3-x-3$ has one variation in sign so there is one positive real zero. $P(-x)=3x^6-4x^5-3x^3+x-3$ has three variations in sign so there can be either three negative zeros or one negative zero.
Upper and Lower Bounds for Real Zeros
Let $P(x)$ be a polynomial with real coefficients.
- If we divide $P(x)$ by $x-a$ ($a>0$) using synthetic division and if the row that contains the quotient and remainder has no negative entry, then $a$ is an upper bound for the real zeros of $P(x)$.
- If we divide $P(x)$ by $x-b$ ($b<0$) using synthetic division and if the row that contains the quotient and remainder has entries that are alternatively nonpositive and nonnegative, then $b$ is a lower bound for the real zeros of $P(x)$.
Example. If we divide $P(x)=3x^6+4x^5+3x^3-x-3$ by $x-1$ then
$$1|\begin{array}{cccccc}
3 & 4 & 3 & 0 & -1 & -3\\
& 3 & 7 & 10 & 10 & 9\\
\hline
3 & 7 & 10 & 10 & 9 & 6
\end{array}$$
Since the row that contains quotient and remainder has no negative entries, 1 is an upper bound for real zeros of $P(x)$. If we divide $P(x)$ by $x-(-2)$ then
$$-2|\begin{array}{cccccc}
3 & 4 & 3 & 0 & -1 & -3\\
& -6 & 4 & -14 & 28 & -54\\
\hline
3 & -2 & 7 & -14 & 27 & -57
\end{array}$$
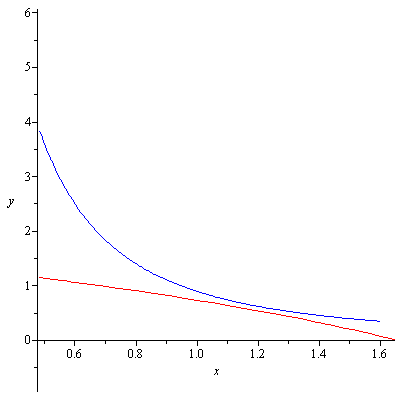
The entries of the row that contains the quotient and remainder are alternatively nonpositive and nonnegative, so $-2$ is a lower bound for real zeros of $P(x)$. $P(x)$ in fact does not have any integer zeros but the upper and lower bounds helps us graphically locate the real zeros of $P(x)$. Also they can be used as initial estimates for Newton’s method, a method that can find approximations to real zeros of a polynomial. Figure 1 shows that there is one positive real zero and one negative real zero of $P(x)$.
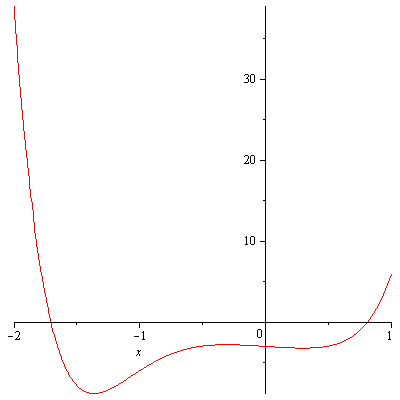
Real zeros of P(x)=3x^6+4x^5+3x^3-x-3